


Flink是什么
流式处理、事件驱动、实时管道、数据处理
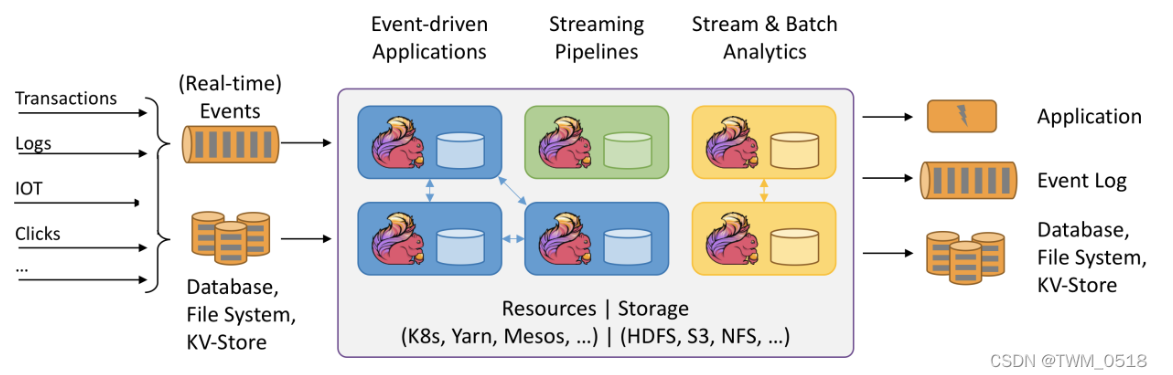
Flink处理的框架如下:
对于批和流的概念:
批处理:攒一批处理一次,hadoop、spark;
流处理:来一个处理一个,flink
Flink好在哪
流更反映生活状态,例如说话一句一句
flink在搭建这种架构时注重流批一体,例如lambda架构:流处理+批处理两套系统,同时保证低延迟和结果准确
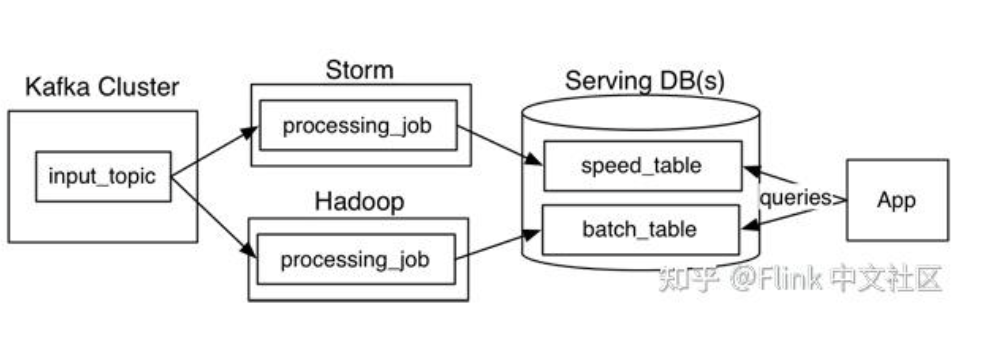
flink用一套架构实现了lambda架构,虽然是流处理,但是通过时间语义保证了准确性,保证精确一次的状态保证
Flink的分层API
根据抽象程度分成三层:
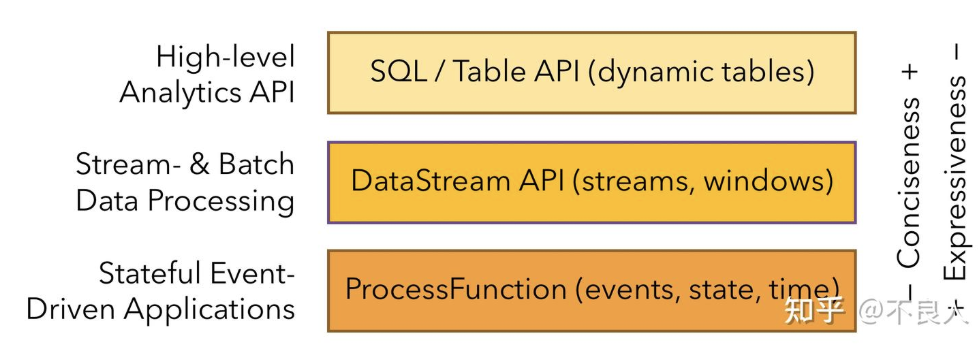
最高层:SQL、TableAPI(声明式领域专用语言),Flink 支持两种关系型的 API,Table API 和 SQL。这两个 API 都是批处理和流处理统一的 API,这意味着在无边界的实时数据流和有边界的历史记录数据流上,关系型 API 会以相同的语义执行查询,并产生相同的结果。Table API 和 SQL 借助了 Apache Calcite 来进行查询的解析,校验以及优化。它们可以与 DataStream 和 DataSet API 无缝集成,并支持用户自定义的标量函数,聚合函数以及表值函数。
核心api:DataStream/DataSet API,为许多通用的流处理操作提供了处理原语。这些操作包括窗口、逐条记录的转换操作,在处理事件时进行外部数据库查询等。DataStream API 支持 Java 和 Scala 语言
底层api:ProcessFunction 是 Flink 所提供的最具表达力的接口。ProcessFunction 可以处理一或两条输入数据流中的单个事件或者归入一个特定窗口内的多个事件。它提供了对于时间和状态的细粒度控制。开发者可以在其中任意地修改状态,也能够注册定时器用以在未来的某一时刻触发回调函数。因此,可以利用 ProcessFunction 实现许多有状态的事件驱动应用所需要的基于单个事件的复杂业务逻辑。
Flink组件架构
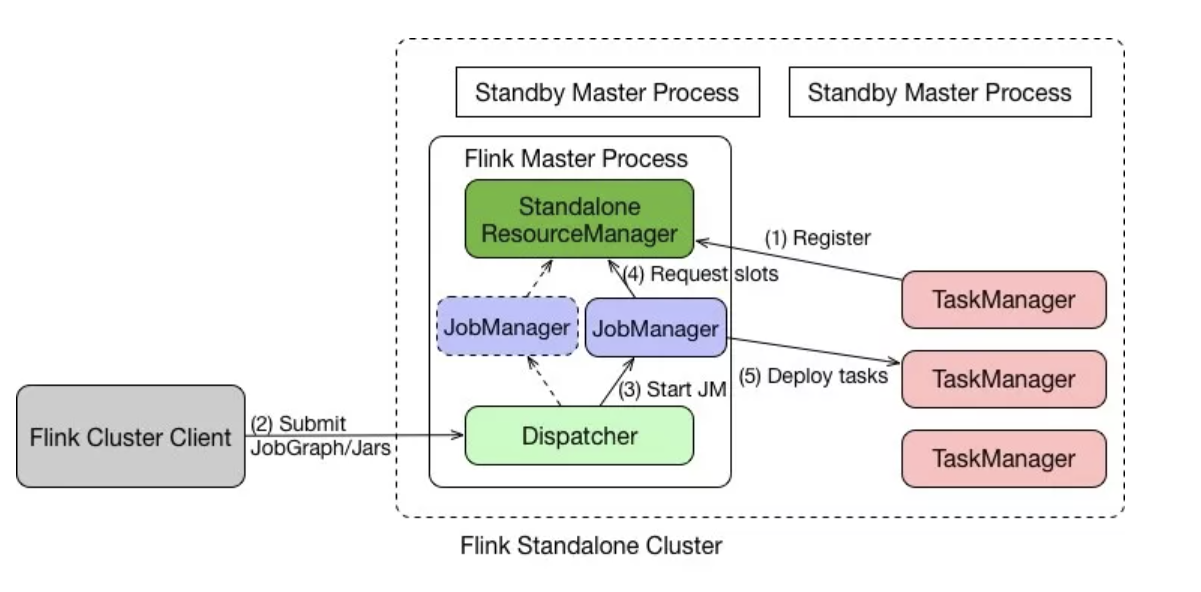
flink工作组成部分有客户端(提交作业)、JobManager(管理Job转换job分发任务)、TaskManager(执行job)
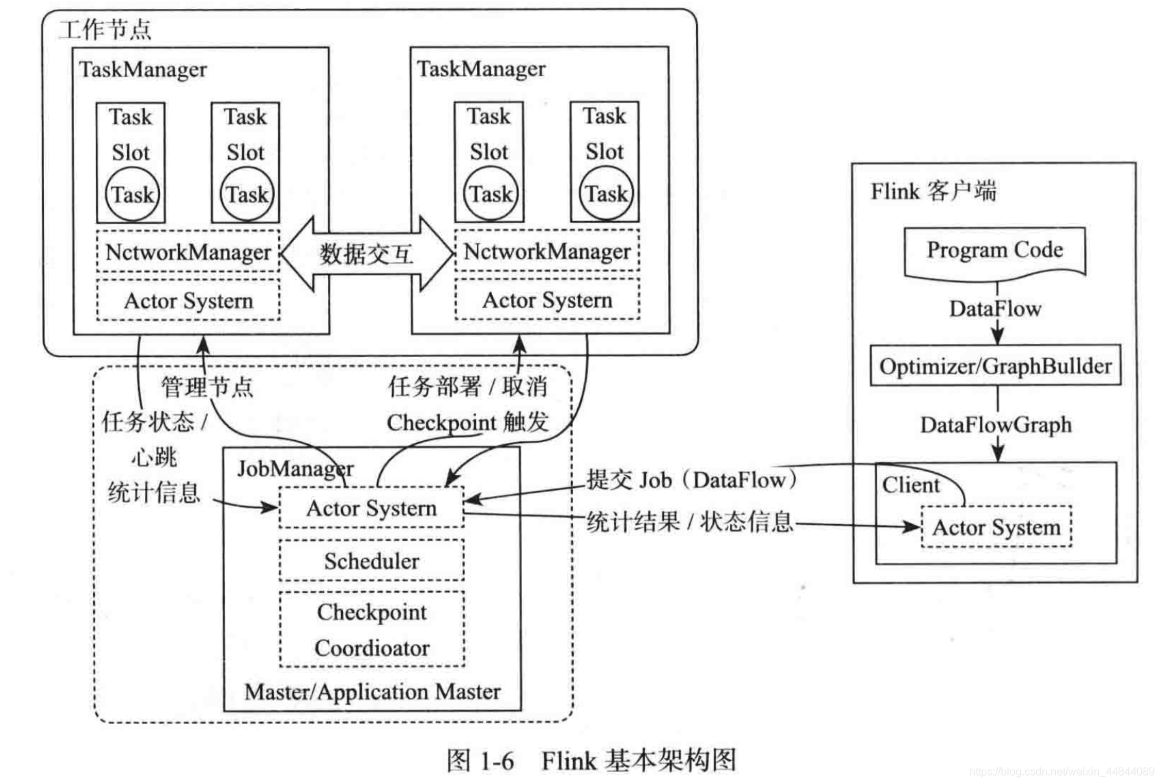
jobManager是核心组件,处理客户端提交的jar、数据流图、作业图,申请资源,分发任务到taskManager,协调操作,检查点协调,内部包含
resourceManager,一个flink集群只有一个,负责分配任务槽slot,一个任务分一个
分发器dispatcher,负责作业提交的接口通信
这些工件以部署形式差异,常见的有两种:
standalone:独立集群,自己承担各个组件
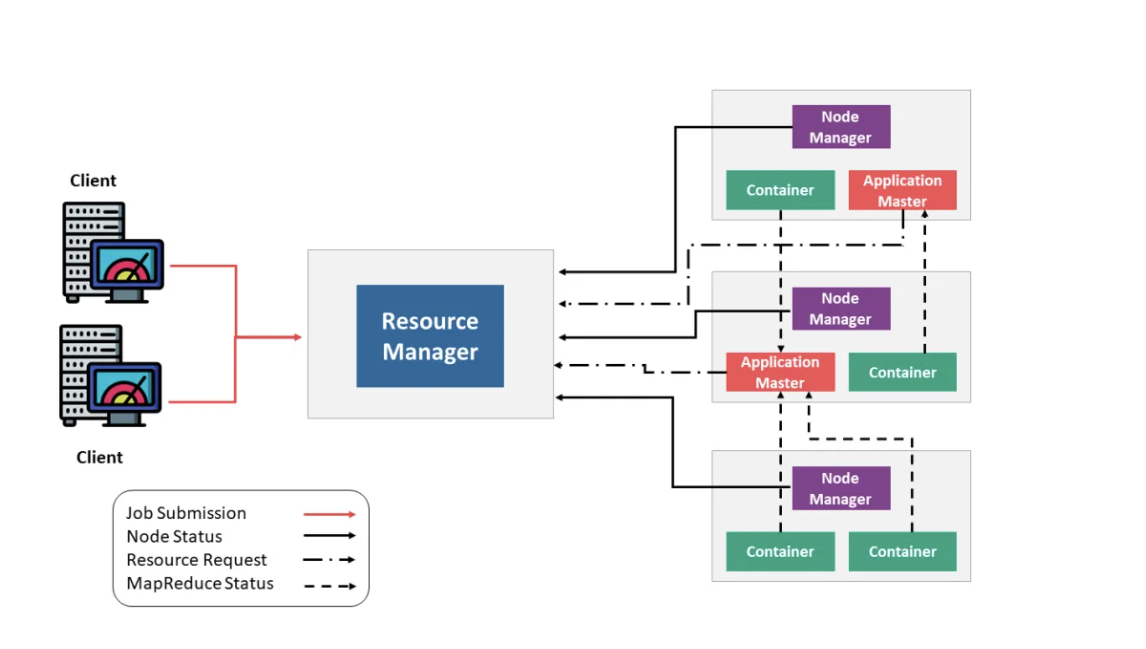
flink on yarn:基于yarn的版本资源管理器集群
Flink命令
flink相关命令
提交flink任务
flink run -m yarn-cluster -yt ssl/ -yjm 1024 -ytm 1024 -ys 4 -p 4 -c com.fatfish.flink.FlinkTestMain ./fink-test-0.0.1-SNAPSHOT.jar查看注册用户
klist注册用户
kinit billing_cdluseryarn相关命令
# 查看任务运行
yarn app -list
# 杀死运行的任务
yarn app -kill [appid]
评论区