


使用案例
post
org.apache.httpcomponents是apache提供的发http请求的包,能够提供简单的restful风格接口请求客户端的代码模板
还需要分析httpclient、spring-restTemplate、servlet、springMVC的区别:
httpclient是http请求客户端的开发包
spring-restTemplate是基于httpclient封装的支持spring框架的http请求开发包
servlet是http请求服务端的开发模板
springMVC是基于servlet构建的,支持spring框架的快速搭建服务端的代码框架
一个基于httpclient开发的带表单参数post方法请求的使用案例如下:
public class DoPOSTParam {
public static void main(String[] args) throws Exception {
// 创建Httpclient对象
CloseableHttpClient httpclient = HttpClients.createDefault();
// 创建http POST请求
HttpPost httpPost = new HttpPost("http://127.0.0.1:433/search");
// 设置2个post参数,一个是scope、一个是name
List<NameValuePair> parameters = new ArrayList<NameValuePair>(0);
parameters.add(new BasicNameValuePair("scope", "project"));
parameters.add(new BasicNameValuePair("q", "java"));
// 构造一个form表单式的实体
UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(parameters);
// 将请求实体设置到httpPost对象中
httpPost.setEntity(formEntity);
//伪装浏览器
httpPost.setHeader("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36");
CloseableHttpResponse response = null;
try {
// 执行请求
response = httpclient.execute(httpPost);
// 判断返回状态是否为200
if (response.getStatusLine().getStatusCode() == 200) {
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
//内容写入文件
FileUtils.writeStringToFile(new File("E:\\devtest\\oschina-param.html"), content, "UTF-8");
System.out.println("内容长度:"+content.length());
}
} finally {
if (response != null) {
response.close();
}
httpclient.close();
}
}
}或者不用表单,以json形式传参:
CloseableHttpClient closeableHttpClient = HttpClients.createDefault();
HttpPost httpPost = new HttpPost("http://speed-api.5.jdtest.net/test-helper/jsf-api-trans");
JSONObject jsonObject = new JSONObject();
jsonObject.put("name", "ty");
jsonObject.put("age", 18);
jsonObject.put("reqParams", JSON.toJSONString(args));
httpPost.setEntity(new StringEntity(jsonObject.toJSONString()));
httpPost.setHeader("Content-Type", "application/json; charset=UTF-8");
CloseableHttpResponse res = closeableHttpClient.execute(httpPost);
String content = EntityUtils.toString(res.getEntity(), "utf-8");其中几个比较核心的点:
构造HttpClient对象的
HttpClients#createDefault(点我跳转) 方法执行请求时的
InternalHttpClient#execute(点我跳转)方法,为什么是InternalHttpClient,是因为HttpClients构造的结果
get
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.URIBuilder;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.net.URI;
public class HttpClientGetExample {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("http://example.com/api/data");
// 添加请求头
httpGet.addHeader("Authorization", "Bearer your_token");
httpGet.addHeader("Content-Type", "application/json");
// 添加 URL 参数
URI uri = new URIBuilder(httpGet.getURI())
.addParameter("param1", "value1")
.addParameter("param2", "value2")
.build();
httpGet.setURI(uri);
// 执行请求HttpClients
createDefault
public static CloseableHttpClient createDefault() {
return HttpClientBuilder.create().build();
}内部可以看到是调用Builder进行构造
除了默认的构造方法,还有一个带参的:custom方法
custom
RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(10000).setSocketTimeout(120000).build();
CloseableHttpClient cusClient= HttpClients.custom()
.setSSLSocketFactory(sslsf)
.setMaxConnTotal(1000)
.setMaxConnPerRoute(1000)
.setDefaultRequestConfig(requestConfig)
.build();public static HttpClientBuilder custom() {
return HttpClientBuilder.create();
}该方法就不调用build了,而是允许调用方自行配置参数
可见核心都在HttpClientBuilder#build(点我跳转)方法中
HttpClientBuilder
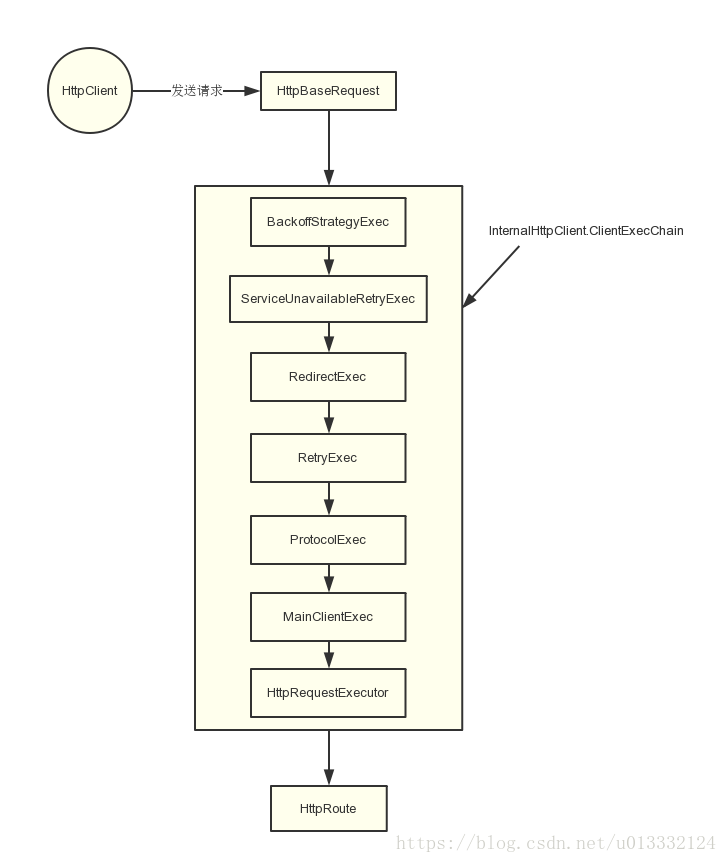
构造HttpClient,同时构造HttpClient的调用链,是链式法则的一个优秀实现
build
拆解build方法,可以大致分为两块:
构建池
构建责任链
构建池
HttpClientConnectionManager connManagerCopy = this.connManager;
if (connManagerCopy == null) {
LayeredConnectionSocketFactory sslSocketFactoryCopy = this.sslSocketFactory;
if (sslSocketFactoryCopy == null) {
……
}
@SuppressWarnings("resource")
final PoolingHttpClientConnectionManager poolingmgr = new PoolingHttpClientConnectionManager(
RegistryBuilder.<ConnectionSocketFactory>create()
.register("http", PlainConnectionSocketFactory.getSocketFactory())
.register("https", sslSocketFactoryCopy)
.build(),
null,
null,
dnsResolver,
connTimeToLive,
connTimeToLiveTimeUnit != null ? connTimeToLiveTimeUnit : TimeUnit.MILLISECONDS);
……
connManagerCopy = poolingmgr;
}
ConnectionReuseStrategy reuseStrategyCopy = this.reuseStrategy;取主动设置的的连接管理对象connManager,如果不存在,才按PoolingHttpClientConnectionManager设置,通过连接工厂创建,存入connManagerCopy。这里参考PoolingHttpClientConnectionManager的构造函数
因此可以看出,不设置连接管理器时,使用HttpClient默认提供的池化管理器
构建责任链
ClientExecChain execChain = createMainExec(
requestExecCopy,
connManagerCopy,
reuseStrategyCopy,
keepAliveStrategyCopy,
new ImmutableHttpProcessor(new RequestTargetHost(), new RequestUserAgent(userAgentCopy)),
targetAuthStrategyCopy,
proxyAuthStrategyCopy,
userTokenHandlerCopy);
execChain = decorateMainExec(execChain);首先构造最底层核心的MainClientExec处理单元,这里参考createMainExec方法
execChain = new ProtocolExec(execChain, httpprocessorCopy);
execChain = decorateProtocolExec(execChain);然后包装到ProtocolExec处理单元
// Add request retry executor, if not disabled
if (!automaticRetriesDisabled) {
HttpRequestRetryHandler retryHandlerCopy = this.retryHandler;
if (retryHandlerCopy == null) {
retryHandlerCopy = DefaultHttpRequestRetryHandler.INSTANCE;
}
execChain = new RetryExec(execChain, retryHandlerCopy);
}判断重试属性,构造RetryExec处理单元
// Optionally, add service unavailable retry executor
final ServiceUnavailableRetryStrategy serviceUnavailStrategyCopy = this.serviceUnavailStrategy;
if (serviceUnavailStrategyCopy != null) {
execChain = new ServiceUnavailableRetryExec(execChain, serviceUnavailStrategyCopy);
}再上层是ServiceUnavailableRetryExec处理单元
// Add redirect executor, if not disabled
if (!redirectHandlingDisabled) {
RedirectStrategy redirectStrategyCopy = this.redirectStrategy;
if (redirectStrategyCopy == null) {
redirectStrategyCopy = DefaultRedirectStrategy.INSTANCE;
}
execChain = new RedirectExec(execChain, routePlannerCopy, redirectStrategyCopy);
}再上层是重定向处理单元
// Optionally, add connection back-off executor
if (this.backoffManager != null && this.connectionBackoffStrategy != null) {
execChain = new BackoffStrategyExec(execChain, this.connectionBackoffStrategy, this.backoffManager);
}再上层是回滚处理单元
return new InternalHttpClient(
execChain,
connManagerCopy,
routePlannerCopy,
cookieSpecRegistryCopy,
authSchemeRegistryCopy,
defaultCookieStore,
defaultCredentialsProvider,
defaultRequestConfig != null ? defaultRequestConfig : RequestConfig.DEFAULT,
closeablesCopy);最后把包装好的处理链构造InternalHttpClient
可以用以下图解来具象责任链:
createMainExec
protected ClientExecChain createMainExec(
final HttpRequestExecutor requestExec,
final HttpClientConnectionManager connManager,
final ConnectionReuseStrategy reuseStrategy,
final ConnectionKeepAliveStrategy keepAliveStrategy,
final HttpProcessor proxyHttpProcessor,
final AuthenticationStrategy targetAuthStrategy,
final AuthenticationStrategy proxyAuthStrategy,
final UserTokenHandler userTokenHandler)
{
return new MainClientExec(
requestExec,
connManager,
reuseStrategy,
keepAliveStrategy,
proxyHttpProcessor,
targetAuthStrategy,
proxyAuthStrategy,
userTokenHandler);
}这里可以看到直接返回的就算MainClientExec,这个处理单元是最核心的,控制着连接池的获取、socket连接的建立、链接的释放,可以说是HttpClient的核心了。它的下层调用是HttpRequestExecutor,里面控制着Http请求头的发送,Http Request Line的发送,以及响应的收集。
InternalHttpClient
execute
继承父类CloseableHttpClient#execute
public CloseableHttpResponse execute(
final HttpHost target,
final HttpRequest request) throws IOException, ClientProtocolException {
return doExecute(target, request, null);
}继续看doExecute
doExecute
final HttpRequestWrapper wrapper = HttpRequestWrapper.wrap(request, target);首先做request和target包装
然后是对请求参数config的设置和localcontext的设置,暂略
final HttpRoute route = determineRoute(target, wrapper, localcontext);到这里是确定路由
return this.execChain.execute(route, wrapper, localcontext, execAware);然后就执行自己的责任链了。根据HttpClientBuilder#build(点我跳转)方法,责任链最上层是都是做配置项判断确定是否执行的,逐层判断,按照build流程,顺序是回滚单元、重定向单元、服务不可用单元、重试单元、核心执行单元
前面三个暂不看,比较核心的到RetryExec这个单元,因为一般重试默认都是开的,参考RetryExec#execute(点我跳转),然后就是最底层的核心执行单元MainClientExec,参考MainClientExec#execute(点我跳转)
RetryExec
execute
for (int execCount = 1;; execCount++) {
try {
return this.requestExecutor.execute(route, request, context, execAware);
} catch (final IOException ex) {
……
retryHandler.retryRequest(ex, execCount, context)
}重试的逻辑较简单,其实就是直接执行下层单元,但是做了catch,即调用失败了,借助retryHandler做重试
这里的retryHandler可以自定义,在HttpClientBuilder类使用set方法进行注入。不指定也有默认值DefaultHttpRequestRetryHandler
MainClientExec - 最核心执行单元
最核心的处理单元,控制着连接池的获取、socket连接的建立、链接的释放,可以说是HttpClient的核心了。
它的下层调用是HttpRequestExecutor,里面控制着Http请求头的发送,Http Request Line的发送,以及响应的收集
execute
AuthState targetAuthState = context.getTargetAuthState();首先是跟Auth相关的内容暂不关注
final ConnectionRequest connRequest = connManager.requestConnection(route, userToken);这里是调用池化连接管理器的PoolingHttpClientConnectionManager#requestConnection(点我跳转)方法获取ConnectionRequest,它是HttpClientConnection和获取连接操作的封装
try {
final int timeout = config.getConnectionRequestTimeout();
managedConn = connRequest.get(timeout > 0 ? timeout : 0, TimeUnit.MILLISECONDS);
} catch... ...获取连接
if (!managedConn.isOpen()) {
this.log.debug("Opening connection " + route);
try {
establishRoute(proxyAuthState, managedConn, route, request, context);
} catch (final TunnelRefusedException ex) {
if (this.log.isDebugEnabled()) {
this.log.debug(ex.getMessage());
}
response = ex.getResponse();
break;
}
}判断一下连接是不是还open的,如果不open了重新建立一下连接
response = requestExecutor.execute(request, managedConn, context);通过requestExecutor执行请求,参考HttpRequestExecutor#execute(点我跳转)
establishRoute
step = this.routeDirector.nextStep(route, fact);这里取到当前连接所处的状态,通过状态判断要做什么,重点关注一下涉及连接池的部分:
case HttpRouteDirector.CONNECT_TARGET:
this.connManager.connect(
managedConn,
route,
timeout > 0 ? timeout : 0,
context);
tracker.connectTarget(route.isSecure());
break;这里的connManager是构造函数传进来的:
public MainClientExec(
final HttpRequestExecutor requestExecutor,
final HttpClientConnectionManager connManager,
final ConnectionReuseStrategy reuseStrategy,
final ConnectionKeepAliveStrategy keepAliveStrategy,
final HttpProcessor proxyHttpProcessor,
final AuthenticationStrategy targetAuthStrategy,
final AuthenticationStrategy proxyAuthStrategy,
final UserTokenHandler userTokenHandler) {
……
this.connManager = connManager;
……
}即前面看过的HttpClientBuilder#build(点我跳转)
// HttpClientBuilder#build
final PoolingHttpClientConnectionManager poolingmgr = new PoolingHttpClientConnectionManager(
RegistryBuilder.<ConnectionSocketFactory>create()
.register("http", PlainConnectionSocketFactory.getSocketFactory())
.register("https", sslSocketFactoryCopy)
.build(),
null,
null,
dnsResolver,
connTimeToLive,
connTimeToLiveTimeUnit != null ? connTimeToLiveTimeUnit : TimeUnit.MILLISECONDS);即PoolingHttpClientConnectionManager#connect(点我跳转)
PoolingHttpClientConnectionManager
连接池的管理器,其中维护了连接池核心变量:
// HttpClient的连接池
private final CPool pool;httpclient构造了两层连接池,是为了应对这种:不同的请求配置,每个请求配置分别进行池化的场景,基于这个CPool体会httpclient是怎么构建两层连接池的
关于池子的实现继续看CPool部分
构造函数
public PoolingHttpClientConnectionManager(
final HttpClientConnectionOperator httpClientConnectionOperator,
final HttpConnectionFactory<HttpRoute, ManagedHttpClientConnection> connFactory,
final long timeToLive, final TimeUnit timeUnit) {
……
this.pool = new CPool(new InternalConnectionFactory(
this.configData, connFactory), 2, 20, timeToLive, timeUnit);
this.pool.setValidateAfterInactivity(2000);
this.connectionOperator = Args.notNull(httpClientConnectionOperator, "HttpClientConnectionOperator");
this.isShutDown = new AtomicBoolean(false);
}构造函数里面关注两个初始化设置,一个是CPool的大小,默认为每个Route两个连接,最多维护20个
requestConnection - 获取请求
final Future<CPoolEntry> future = this.pool.lease(route, state, null);首先调用池的lease方法租借连接得到CPoolEntry,它是池中对象,也就是一个实际connection的抽象
return new ConnectionRequest() {
……
final HttpClientConnection conn = leaseConnection(future, timeout, timeUnit);返回请求的连接的封装类ConnectionRequest,其中构造的时候leaseConnection是核心方法
leaseConnection
return CPoolProxy.newProxy(entry);可以看到这里最终拿到的连接,实际上返回的是CPoolEntry的代理类
connect
public void connect(
final HttpClientConnection managedConn,
final HttpRoute route,
final int connectTimeout,
final HttpContext context) throws IOException {
Args.notNull(managedConn, "Managed Connection");
Args.notNull(route, "HTTP route");
final ManagedHttpClientConnection conn;
synchronized (managedConn) {
final CPoolEntry entry = CPoolProxy.getPoolEntry(managedConn);
conn = entry.getConnection();
}
final HttpHost host;
if (route.getProxyHost() != null) {
host = route.getProxyHost();
} else {
host = route.getTargetHost();
}
this.connectionOperator.connect(
conn, host, route.getLocalSocketAddress(), connectTimeout, resolveSocketConfig(host), context);
}可以看到,优先从cPool里面取连接,即池化的应用
下面基于DefaultHttpClientConnectionOperator#connect 完成连接
// DefaultHttpClientConnectionOperator#connect
public void connect(
final ManagedHttpClientConnection conn,
final HttpHost host,
final InetSocketAddress localAddress,
final int connectTimeout,
final SocketConfig socketConfig,
final HttpContext context) throws IOException {
……
Socket sock = sf.createSocket(context);
……
if (linger >= 0) {
sock.setSoLinger(true, linger);
}
conn.bind(sock);
final InetSocketAddress remoteAddress = new InetSocketAddress(address, port);
if (this.log.isDebugEnabled()) {
this.log.debug("Connecting to " + remoteAddress);
}
try {
sock = sf.connectSocket(
connectTimeout, sock, host, remoteAddress, localAddress, context);
conn.bind(sock);
……
} catch ……
}可以看到是socket编程了,这里就是最底层了
CPool - HttpClient的连接池
CPool实现自AbstractConnPool,是HttpClient中维护connection连接的池子,CPool架构模式如下:
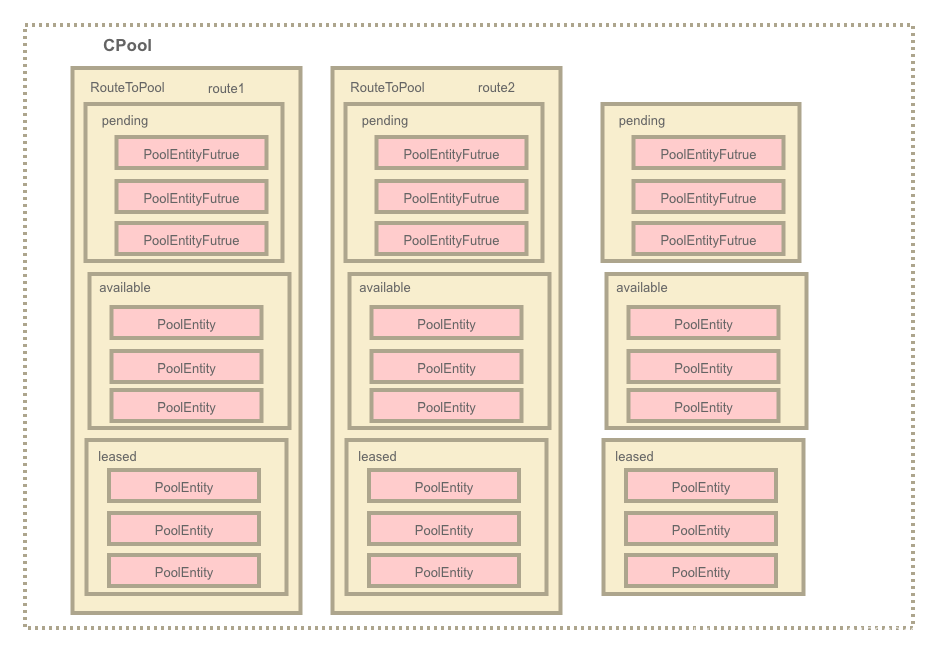
CPool连接池是一层大池子,它会为每个httpRoute单独的维护一个连接池routeToPool二层小池子,管理着available、leased、pending这些对象。同时CPool本身也会维护一个总的available、leased、pending对象,是那些routeToPool中available、leased、pending的总和
其他概念如下:
available:可用连接对象PoolEntity
leased:已被的连接租借对象PoolEntity
pending:存放等待获取连接的线程的Future<PoolEntity>
可用参考其定义分析其核心成员变量:
// 继承自AbstractConnPool
// 二层小池子
private final Map<T, RouteSpecificPool<T, C, E>> routeToPool;
// 已被租借列表
private final Set<E> leased;
// 可用列表
private final LinkedList<E> available;
// 等待租借成功的线程
private final LinkedList<Future<E>> pending;CPool也是一个双层池子池化的非常好的案例,跟apache.pool2中的GenericObjectPool可以一起比较学习:
lease - 租借方法
继承自父类AbstractConnPool
分析下是怎么通过Route找到对应的RouteToPool二层小池子的
return new Future<E>() {
……
@Override
public E get(final long timeout, final TimeUnit timeUnit) throws InterruptedException, ExecutionException, TimeoutExce
for (;;) {
synchronized (this) {
try {
……
final E leasedEntry = getPoolEntryBlocking(route, state, timeout, timeUnit, this);
if (validateAfterInactivity > 0) {
if (leasedEntry.getUpdated() + validateAfterInactivity <= System.currentTimeMillis()) {
if (!validate(leasedEntry)) {
leasedEntry.close();
release(leasedEntry, false);
continue;
}
}
}
……
} catch ……
}
}
}
};直接返回了一个Future类,其中定义了多个方法,get方法调用getPoolEntryBlocking方法获取PoolEntry对象,并且校验对象的可用性
getPoolEntryBlocking
this.lock.lock();
try {
E entry;
for (;;) {
……
// 根据路由信息获取池子
final RouteSpecificPool<T, C, E> pool = getPool(route);
……
}这里有一步加锁操作,因为RouteSpecificPool小池子是线程不安全的,具体可用看小池子的方法。加锁完成后直接起两个for循环,根据route获取二层的RouteSpecificPool小池子, getPool方法见后面
for (;;) {
entry = pool.getFree(state);
if (entry == null) {
break;
}
if (entry.isExpired(System.currentTimeMillis())) {
entry.close();
}
if (entry.isClosed()) {
this.available.remove(entry);
pool.free(entry, false);
} else {
break;
}
}二层for循环,在循环里面持续调用小池子的getFree方法,然后判断取到的entry的状态,非null非关闭非过期的连接,直接break循环
if (entry != null) {
this.available.remove(entry);
this.leased.add(entry);
onReuse(entry);
return entry;
}跳出循环后处理把连接移除可用组,存入借出组,然后返回这个连接,否则走到判断perRoute参数的流程,即每个Route最多同时借出多少个连接
// New connection is needed
final int maxPerRoute = getMax(route);
// Shrink the pool prior to allocating a new connection
final int excess = Math.max(0, pool.getAllocatedCount() + 1 - maxPerRoute);如果上面拿不到可用连接了,后面就要开始建新连接:
// New connection is needed
final int maxPerRoute = getMax(route);
// Shrink the pool prior to allocating a new connection
final int excess = Math.max(0, pool.getAllocatedCount() + 1 - maxPerRoute);这里先取池能力,然后就是判断几种场景:
条件一、目前已分配的已经超过了最大容量
if (excess > 0) {
for (int i = 0; i < excess; i++) {
final E lastUsed = pool.getLastUsed();
if (lastUsed == null) {
break;
}
lastUsed.close();
this.available.remove(lastUsed);
pool.remove(lastUsed);
}
}首先比较小池子已经分配的数量,内部方法看看到是available+leased,如果超了maxPerRoute属性,即0和两个值的差+1相比,后者更大,这时执行清理操作,把可用区最后一个关掉,如果可用区没有最后一个了,就先不关了直接break
条件二、目前已分配的小于最大容量,且有空余
if (pool.getAllocatedCount() < maxPerRoute) {
final int totalUsed = this.leased.size();
final int freeCapacity = Math.max(this.maxTotal - totalUsed, 0);
if (freeCapacity > 0) {
final int totalAvailable = this.available.size();
if (totalAvailable > freeCapacity - 1) {
final E lastUsed = this.available.removeLast();
lastUsed.close();
final RouteSpecificPool<T, C, E> otherpool = getPool(lastUsed.getRoute());
otherpool.remove(lastUsed);
}
final C conn = this.connFactory.create(route);
entry = pool.add(conn);
this.leased.add(entry);
return entry;
}
}这个条件下,如果已分配的数量小于maxPerRoute,且还有余量,通过工厂类执行create操作,然后调用小池子的add方法存入conn,并且把新create给返回去
条件三、目前已分配的与最大容量相等
try {
pool.queue(future);
this.pending.add(future);
if (deadline != null) {
success = this.condition.awaitUntil(deadline);
} else {
this.condition.await();
success = true;
}
if (future.isCancelled()) {
throw new ExecutionException(operationAborted());
}
} finally {
// In case of 'success', we were woken up by the
// connection pool and should now have a connection
// waiting for us, or else we're shutting down.
// Just continue in the loop, both cases are checked.
pool.unqueue(future);
this.pending.remove(future);
}最后一个条件,已分配数量与maxPerRoute相等,且也没有余量了即前面都没取到,这里就把future存入大小池子的pending队列中,并且通过一个condition进行阻塞,这里还是AQS里面的Condition逻辑,参考以下文章:
这里需要注意的是:HttpClient的超时只是校验SSL超时,如果因为maxPerRoute不够了,线程在这里做condition阻塞了,是不会校验SSL超时的,但是可能会计算总的请求时间,因此会出现超时5s,但实际执行了12s还返回的场景
另外,最后一个finally包裹,意思是不管这里是被condition激活的,还是用于请求的future超时被cancelled了,都会执行finally里面的代码块,移出pending队列,然后返回一层for循环的开头,重新走一遍获取连接的流程
getPool - 获取小池子
private RouteSpecificPool<T, C, E> getPool(final T route) {
RouteSpecificPool<T, C, E> pool = this.routeToPool.get(route);
if (pool == null) {
pool = new RouteSpecificPool<T, C, E>(route) {
@Override
protected E createEntry(final C conn) {
return AbstractConnPool.this.createEntry(route, conn);
}
};
this.routeToPool.put(route, pool);
}
return pool;
}从map中get流程不多说,重点关注取不到的情况
这里直接new一个新的小池子,小池子实现了createEntry方法,调用点在小池子的add方法,这里就呼应了getPoolEntryBlocking中maxPerRoute的条件二的添加流程。这里小池子的createEntry调用的是AbstractConnPool的createEntry,实际实现在CPool里面
release - 归还流程
final RouteSpecificPool<T, C, E> pool = getPool(entry.getRoute());
pool.free(entry, reusable);获取小池子,执行free操作
if (reusable && !this.isShutDown) {
this.available.addFirst(entry);
} else {
entry.close();
}然后校验可用性,如果可用,归还,不可用则直接关闭掉
if (future != null) {
this.condition.signalAll();
}最后判断pending队列中还有future,即阻塞的拿不到连接的,有的话,移出去,执行唤醒全部的操作,这里被唤醒的是多条,因为是condition的流程,又会重新竞争AQS锁,拿到锁的申请获取连接,拿不到的等,直到开始一直拿不到,再次顺序存入pending中
free - 移出操作
free操作一定做借出队列的移出操作,但不一定做可用队列的移出操作,因为不一定可用
createEntry - 构造连接封装类
return new CPoolEntry(this.log, id, route, conn, this.timeToLive, this.timeUnit);核心就是通过预置参数构造一个CPoolEntry封装类,这里就可用看封装类到底封装了什么了
CPoolEntry/PoolEntry - 连接的封装类
池对象的封装,通过成员变量分析下:
// 最核心的两个,一个是大池子的mapkey,路由信息,一个是实际d连接
this.route = route;
this.conn = conn;HttpRequestExecutor
execute
public HttpResponse execute(
final HttpRequest request,
final HttpClientConnection conn,
final HttpContext context) throws IOException, HttpException {
Args.notNull(request, "HTTP request");
Args.notNull(conn, "Client connection");
Args.notNull(context, "HTTP context");
try {
HttpResponse response = doSendRequest(request, conn, context);
if (response == null) {
response = doReceiveResponse(request, conn, context);
}
return response;
} catch ……
}实现发送req和接收rsp的方法,不再细看
评论区