


流的分类
Closeable - 顶层接口
含义就如其名字,即“可以关闭的”
Closeable代表一个持有资源的抽象对象,是可以关闭的数据的源或目标。调用 close 方法以释放对象持有的资源
public void close() throws IOException;流的设计模式
流采取的是装饰器模式+适配器模式
装饰器模式:字节流和字符流分别采用了抽象顶层类+实现类+装饰器,即首先提供一些基本能力,然后在这些基本能力的基础上包装成各种装饰器
适配器模式:字节流和字符流之间的互通使用的是适配器模式
这就导致了流家族种类繁多,使用的时候需要一层一层嵌套
另一个经典的装饰器模式是guava线程装饰器
ListeningExecutorService listeningExecutorService = MoreExecutors.listeningDecorator(fixedThreadPoolExecutor);理解流的设计模式能够更好地理解流的分类和各种实现
流的分类与作用
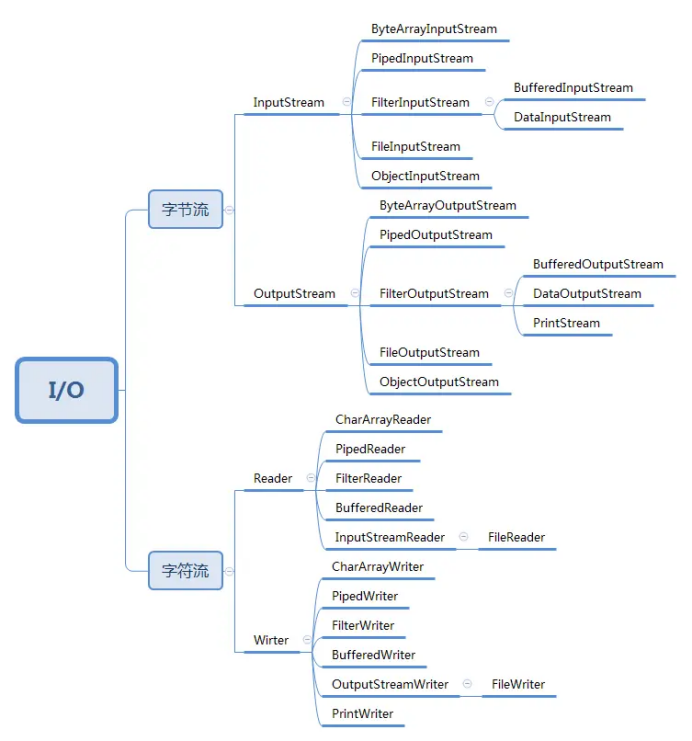
四个顶层抽象类
流按照方向可以分为:
输入流:从文件读到内存,只能进行读操作。输入流不会创建文件
输出流:从内存读到文件,只能进行写操作。输出流会帮我们创建文件
流按照处理数据单元可以分为:
字符流:以字符为单位,只能读字符类型,处理的最基本单元是Unicode码元,每次读入或读出2字节(16位数据),java代码接收一般为char数组,也可以写别的
字符流在输出前实际上是要完成Unicode码元序列到相应编码方式的字节序列的转换,所以它会使用内存缓冲区来存放转换后得到的字节序列,等待都转换完毕再一同写入磁盘文件中
字节流:以字节为单位,常用来处理二进制数据,因此可以读任何数据例如图片、文件、音乐等等,每次读入或读出8bit数据,java代码接收只能是byte
因此常用byte[]和字节流做一些内存方面的限制,例如byte[1024]就可以轻松限制一个1KB的内存占用
在这两种基本分类两两组合的场景下,就有了io里面的四个最顶层的抽象类:
InputStream:字节输入流OutputStream:字节输出流Reader:字符输入流Writer:字符输出流
下层实现类
流按照功能分类可以分为:
节点流:直接与数据源相连,读入或读出
处理流:对已存在的流进行封装,通过封装的流的功能调用实现数据读写,例如我给流加个Buffering缓冲区(类似于后端和mysql之间的redis)
上面讲过,流采用的是装饰器模式,即提供一个基本能力,然后提供一个装饰器,在基本能力上进行封装。
这其中,节点流就是基本能力,提供的是直连数据源进行读入读出的能力,例如直连文件的FileInputStream和FileOutStream
处理流是装饰器,对接的是流,即在节点流的基础上进行封装出具备不同能力的高级流,例如提供缓冲能力的BufferedInputStream和BufferedOutputStream
字节流InputStream和OutputStream
顶层抽象类的模板方法
InputStream作为输入流,其核心方法一定是read()方法,除此之外,还有以下:
public int read() // 从输入流中的当前位置读入一个字节(8b)的二进制数据,然后以此数据位低位字节,
// 配上8个全0的高位字节合成一个16位的整型量(0~255)返回调用此方法的语句,若输入流中的当前位置没有数据,则返回-1
public int read(byte[] b) // 从输入流中的当前位置连续读入多个字节保存在数组b中,同时返回所读到的字节数
public int read(byte[] b,int off,int len) // 从输入流中的当前位置连续读入len个字节,保存在数组b中
public int available() // 返回输出流中可以读取的字节数
public long skip(long n) // 使位置指针从当前位置向后跳n个字节
public void mark(int readlimit) // 在当前位置处做一处标记,并且在输入流中读取readlimit个字节数后该标记消失
public void reset() // 将位置执政返回到标记位置
public void close() // 关闭输入流与外设的连接并释放所占用的系统资源
OutputStream作为输出流,其核心方法是write(),除此之外,还有以下:
public void write(int b) // 将参数b的低位字节写入到输出流
public void write(byte[] b) // 将字节数组b的全部字节按顺序写入到输出流
public void write(byte[] b,int off,int len) // 将字节数组b中第off+1个元素开始的len个数据,顺序地写入到输出流
public void flush() // 强制清空缓冲区并执行向外设写操作
public void close() // 关闭输出流与外设的连接并释放所占用的系统资源read系列方法
public abstract int read() throws IOException;read()方法是一个抽象方法,由各个流的实现类自行实现
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}read(byte b[])方法调用的是read(byte[] b,int off,int len) 方法
public int read(byte b[], int off, int len) throws IOException {
Objects.checkFromIndexSize(off, len, b.length);
// 排除byte数组长度为0的场景
if (len == 0) {
return 0;
}
// 尝试读取第一个字节,如果接为-1说明没有内容,直接返回
int c = read();
if (c == -1) {
return -1;
}
// off是游标,在特定游标存入刚刚读到的字节c
b[off] = (byte)c;
// 因为上面已经占了一位了,所以i从1开始,没有从0开始
int i = 1;
try {
// 循环执行read和存储,直到byte[]数组占满,就不再进行读取了
for (; i < len ; i++) {
c = read();
// 如果读不到数据了也会跳出循环
if (c == -1) {
break;
}
b[off + i] = (byte)c;
}
} catch (IOException ee) {
}
return i;
}可以看出来:
首先,InputStream中完成了读取和存入byte[]的骨架,真正读取的方法read()是抽象方法,还是依赖具体的子类去实现
其次,字节流读取存入byte[]中,会读取到数组占满或已经读不到数据了
write系列方法
跟read方法逻辑大体一致
public void write(byte b[], int off, int len) throws IOException {
Objects.checkFromIndexSize(off, len, b.length);
// len == 0 condition implicitly handled by loop bounds
for (int i = 0 ; i < len ; i++) {
write(b[off + i]);
}
}可以看到,也是把byte[]数组中的数据循环执行write(int i)方法,而其具体代码留给实现类取写
其他方法
例如InputStream中的close()、reset()等,OutputStream中的close()、flush()等,提供的都是抽象方法,留给子类实现
字节流的节点流实现
FileInputStream/FileOutputStream - 文件输入/输出流
FileInputStream和FileOutStream分别是InputStream和OutputStream的直接子类,这两个子类主要负责完成对本地磁盘文件的顺序输入与输出操作的流。
FileInputStream类对象表示一个文件字节输入流,从中可读取一个字节或一批字节。在生成FileInputStream类的对象时,若指定的文件找不到,会抛出一个FileNotException异常,该异常必须捕获声明抛出FileNotFoundException异常,该异常必须捕获或声明抛出。
FileInputStream类对象表示一个文件字节输出流,从向流中写入一个字节或一批字节。在生成FileOutputStream类的对象时,若指定的文件不存在则创建一个新的文件,若已存在,则清除原文件的内容。在文件读写操作时会产生IOException异常,该异常必须捕获或声明抛出。
示例
// 利用文件读/写完成图像的复制,将风景.jpg复制为风景1.jpg
public class PictureCopy {
public static void main(String[] args)throws IOException
{
try(
FileInputStream fi = new FileInputStream("风景.jpg");
FileOutputStream fo = new FileOutputStream("风景1.jpg");
)
{
System.out.println("文件的大小是:"+fi.available());
byte[] b= new byte[fi.available()];//输出文件大小
fi.read(b);//创建byte型的数组
fo.write(b);//将图像文件读入b数组
System.out.print("文件已被复制并更改");
}
}
}
//复制的文件在当前(F:\Java10)的文件夹下
//切记要把所复制的图片的也放入到同一个工程中read方法和write方法的实现
// FileInputStream
public int read() throws IOException {
return read0();
}
private native int read0() throws IOException;
// FileOutputStream
public void write(int b) throws IOException {
write(b, fdAccess.getAppend(fd));
}
private native void write(int b, boolean append) throws IOException;这里的实现都是通过native方法完成的
PipedInputStream/PipedOutputStream - 管道输入/输出流
管道字节输入流PipedInputStream和管道字节输出流PipedOutputStream类提供了利用管道方式进行数据输入输出管理的类。管道流用来将一个程序或线程的输出连接到另一个程序或线程作为输入,使得相连线程能够通够PipedInputStream和PipedOuyoutStream流进行数据交换,从而可以实现程序内部线程间的通讯或不同程序间的通信。
PipedInputStream和PipedOutoutStream类分别是InputStream和OutputStream的直接子类。这两个类必须结合使用,其中,管道输入流作为管道的接收端、管道输出流作为管道发送端,在程序设计中应注意数据的传输方法。
构造方法
// 第一种,基于流构造
PipedInputStream(PipedOutputStream src) // 创建一个管道字节输入流,并将其连接到src指定的管道字节输出流。
PipedOutputStream(PipedInputStream src) // 创建一个管道字节输出流,并将其连接到src指定的管道字节输入流。
// 第二种,基于连接方法
connect()实际应用
线程间通信使用的是管道流,参考《java并发编程的艺术》阅读笔记部分
ByteArrayInputStream/ByteArrayOutputStream - 字节数组输入/输出流
提供字节数组的输入输出能力和缓冲能力
ByteArrayInputStream 的内部额外的定义了一个计数器,它被用来跟踪
read()方法要读取的下一个字节。它包含一个内部缓冲区,该缓冲区包含从流中读取的字节。也就是说,它内部维护一个数组,输出的数据会放入它内部数组中。类似的,ByteArrayOutputStream 创建对象下面的构造方法创建一个 32 字节(默认大小)的缓冲区
构造
public class ByteArrayInputStream extends InputStream {
protected byte buf[];
public ByteArrayInputStream(byte buf[]) {
this.buf = buf;
this.pos = 0;
this.count = buf.length;
}
}public class ByteArrayOutputStream extends OutputStream {
protected byte buf[];
public ByteArrayOutputStream(int size) {
if (size < 0) {
throw new IllegalArgumentException("Negative initial size: "
+ size);
}
buf = new byte[size];
}
}从二者的构造函数上可以看出其维护缓冲的逻辑
字节流的处理流实现
FilterInputStream/FilterOutputStream - 过滤输入/输出流
分别实现了在数据的读、写操作的同时进行数据处理,它们是InpuStrem和OutpuStrem类的直接子类,是很多处理流的模板类,很多处理流都是基于这个来实现的,例如DataInputStream/DataOutputStream、BufferedInputStream/BufferedOutputStream
过滤字节输人输出流的主要特点是,过滤字节输入输出流是建立在基本输入输出流之上,并在输人输出数据的同时能对所传输的数据做指定类型或格式的转换,即可实现对二进制字节数据的理解和编码转换
public class FilterInputStream extends InputStream {
protected volatile InputStream in;
protected FilterInputStream(InputStream in) {
this.in = in;
}
public int read() throws IOException {
return in.read();
}
}以FilterInputStream为例,它在构造的时候封装了一个InputStream,在read的时候直接调用in.read()方法
可见它的涉及理念是提供一个包装,或者说提供一个能力的桥梁
DataInputStream/DataOutputStream - 数据处理输入/输出流
基于FilterStream实现,主要作用是实现不同数据类型的读取/写入操作
DataInputStream和DataInputStream分别实现了DataInput和DataOutput两个接口中定义的独立于具体机器的带格式的读写操作,从而实现了对不同类型数据的读写
案例
public class DATAOutputStreamTest {
public static void main(String[] args)
{
try(FileOutputStream fout=new FileOutputStream("E:/cqj/myfile1.txt");
DataOutputStream dout=new DataOutputStream(fout);
)
{
dout.writeInt(10);
dout.writeLong(123456);
dout.writeFloat(3.14159926f);
dout.writeDouble(987654321.321);
dout.writeBoolean(true);
dout.writeChars("GoodBye!");
}
catch(IOException e){}
try
(
// 作为装饰器,DataInputStream必须装饰在一个节点流上使用
FileInputStream fin=new FileInputStream("E:/cqj/myfile1.txt");
DataInputStream din=new DataInputStream(fin);
)
{
System.out.println(din.readInt());
System.out.println(din.readLong());
System.out.println(din.readFloat());
System.out.println(din.readDouble());
System.out.println(din.readBoolean());
char ch;
while((ch=din.readChar())!='\0')
System.out.print(ch);
}
catch(FileNotFoundException e)
{
System.out.println("文件我找到!");
}
catch(IOException e) {}
}
}以上案例将不同数据类型写入txt文件,并从该文件中读取并转化为不同的数据类型
从使用上可以看出,处理流是作为装饰器,装饰基本流使用的
BufferedInputStream/BufferedOutputStream - 缓冲输入/输出流
基于FilterStream实现,主要作用是提供流的缓冲能力
BufferedInputStream的构造函数
public class BufferedInputStream extends FilterInputStream {
private static int DEFAULT_BUFFER_SIZE = 8192;
private static final Unsafe U = Unsafe.getUnsafe();
private static final long BUF_OFFSET = U.objectFieldOffset(BufferedInputStream.class, "buf");
// 核心变量count代表目前缓冲区里面大于最后一个有效数据的索引,如果缓冲区为空即0,缓冲区满则为buf.length
protected int count;
// 缓冲区的当前位置,代表下一次read要从缓冲区拿取的数据位置
protected int pos;
protected volatile byte[] buf;
public BufferedInputStream(InputStream in, int size) {
// 调用FilterInputStream的构造方法,持有被装饰的输入流的引用
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
// 构造缓冲数组
buf = new byte[size];
}
}
可以看到缓冲流中也有一个byte[]数组作为写入和写出时的缓冲区,默认长度为8192,除非自行指定长度构造
同时与其父类FilterInputStream一样,持有其装饰对象的引用
BufferedInputStream#read()
public synchronized int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
}pos代表本次read()方法要从缓冲区拿取的字符索引,如果pos>=count 说明当前缓冲区没有可用数据,执行fill()读取,如果读完了还没有,则说明没有东西可以读了
BufferedInputStream#fill()
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;读取的核心方法,可以看到先让count=pos标识之前的都读过了,然后调用InputStream#read(),通过数组读取,存到内存中,然后后置count的值
System.in/System.out - 标准输入/输出流
System.in、System.out、System.err这三个标准的输入与输出流对象定义在java.lang.System类中
标准输入:Java语言的标准输入System.in是BufferedInputStream类的对象。
标准输出:Java语言的标准输出System.out是打印输出流PrintStream类的对象。PrintStream类是过滤流字节输出流FilterOutputStream的子类。
标准错误输出:标准错误输出System.err用于为用户显示错误信息。也是有PrintStream类派生的错误流类。
SequenceInputStream - 顺序输入流
顺序输入流类SequenceInputStream是InputStream的直接子类,其功能是将多个顺序连接在一起,形成单一的输入数据流,没有对应的输出数据流存在
字符流Reader和Writer
Reader和Writer继承层次结构主要是为了国际化,因为字节流InputStream和OutputStream只能支持8位bit流,对于16位的Unicode字符处理性能不佳
顶层抽象类的模板方法
Reader与InputStream一样,提供的方法都是以read为主
// 读到缓冲区
public int read(CharBuffer target)
// 读取字符(-1,0~65535)
public int read()
// 读到字符数组
public int read(char[] cbuf)
// 抽象类,提供给子类实现
public abstract int read(char[] cbuf, int off, int len)除了一些正常的构造函数,Reader提供另一个特殊构造函数,是一个不读取任何字符的Reader
public static Reader nullReader();Writer与OutputStream一样,提供的方法都是以write为主
// 写入字符
public void write(int c)
// 写入字符数组中的所有字符
public void write(char cbuf[])
// 写入String表示的所有字符
public void write(String str)
// 给子类实现
public abstract void write(char cbuf[], int off, int len)与Reader一样,也提供了一个丢弃所有字符的构造函数
public static Writer nullWriter()字符流的节点流实现
InputStreamReader/OutputStreamWriter - 流适配器
因为字符流和字节流出现了顶层的差异,想要让二者做适配,必须使用适配器设计模式,因此就有了流适配器,因此流适配器是字符流的节点流实现,它对接的是字节流
但是换个思路讲,流适配器是字节流的处理流实现,它将字节流封装成字符流
如果想反向封装,可以直接使用String::getBytes()方法
示例
通过字节流读取文件
InputStream inputStream = new FileInputStream("D:\\test\\1.txt");
Reader inputStreamReader = new InputStreamReader(inputStream, "UTF-8");
int data = inputStreamReader.read();
while (data != -1) {
char c = (char) data;
System.out.print(c);
data = inputStreamReader.read();
}
inputStreamReader.close();构造函数
public class InputStreamReader extends Reader {
private final StreamDecoder sd;
public InputStreamReader(InputStream in, String charsetName) throws UnsupportedEncodingException {
super(in);
if (charsetName == null)
throw new NullPointerException("charsetName");
sd = StreamDecoder.forInputStreamReader(in, this, charsetName);
}
}
public class OutputStreamWriter extends Writer {
private final StreamEncoder se;
public OutputStreamWriter(OutputStream out, String charsetName) throws UnsupportedEncodingException {
super(out);
if (charsetName == null)
throw new NullPointerException("charsetName");
se = StreamEncoder.forOutputStreamWriter(out, this, charsetName);
}
}流适配器构造函数中有一个charsetName,作为字符编码,如果不传,则调用Charset.defaultCharset()取一个默认编码
看一看看到在适配器里面封装了一个StreamDecoer和一个StreamEncoder,是作为流编码的工具,其read/write函数都是基于编码工具实现的
FileReader/FileWriter - 文件读写流
FileReader类使得可以将文件的内容作为字符流读取。 它的工作方式与 FileInputStream 非常相似,只是 FileInputStream 读取字节,而 FileReader 读取字符。
FileReader用默认编码读取文件,如果需要指定编码,则必须使用流适配器带编码的构造模式了
FileWriter 类可以将字符写入文件。 在这方面它的工作原理与 FileOutputStream 非常相似,只是 FileOutputStream 是基于字节的,而 FileWriter 是基于字符的。
创建 FileWriter 时,可以决定是否要覆盖具有相同名称的任何现有文件,或者只是要追加内容到现有文件。 可以通过选择使用的 FileWriter 构造函数来决定。
同样编码的选择也要通过流适配器实现。
示例
通过FileReader和FileWriter读写文件
public class FileRW {
public static void main(String[] args) throws IOException {
// 默认是覆盖模式
File file = new File("D:\\test\\1.txt");
Writer writer1 = new FileWriter(file);
writer1.write("string from writer1, ");
writer1.close();
Writer writer2 = new FileWriter(file, true);
writer2.write("append content from writer2");
writer2.close();
Reader reader = new FileReader(file);
int data = reader.read();
while (data != -1) {
// 将会输出 string from writer1, append content from writer2
System.out.print((char) data);
data = reader.read();
}
reader.close();
}
}注意,只要成功 new 了一个 FileWriter 对象,没有指定是追加模式的话,那不管有没有调用 write() 方法,都会清空文件内容
PipedReader/PipedWriter - 管道读写
PipedReader 类使得可以将管道的内容作为字符流读取。 因此它的工作方式与 PipedInputStream 非常相似,只是PipedInputStream 是基于字节的,而不是基于字符的。 换句话说,PipedReader 旨在读取文本。PipedWriter 同理。
PipedReader 必须连接到 PipedWriter 才可以读 ,PipedWriter 也必须始终连接到 PipedReader 才可以写。就是说读写之前,必须先建立连接,有两种方式可以建立连接。
通过构造器创建,伪代码如
Piped piped1 = new Piped(piped2);调用其中一个的 connect() 方法,伪代码如
Piped1.connect(Piped2);
并且通常,PipedReader 和 PipedWriter 由不同的线程使用。 注意只有一个 PipedReader 可以连接到同一个 PipedWriter ,一个简单但没有使用多线程的示例如下:
PipedWriter writer = new PipedWriter();
PipedReader reader = new PipedReader(writer);
writer.write("string form pipedwriter");
writer.close();
int data = reader.read();
while (data != -1) {
System.out.print((char) data); // string form pipedwriter
data = reader.read();
}
reader.close();CharArrayReader/CharArrayWriter - 读写字符串
与ByteArrayInputStream/ByteArrayOutputStream的用法基本一致,差别在于一个是对字节的处理,一个是对字符的处理
CharArrayReader 类可以将 char 数组的内容作为字符流读取,只需将 char 数组包装在 CharArrayReader 中就可以很方便的生成一个 Reader 对象
CharArrayWriter 类可以通过 Writer 方法(CharArrayWriter是Writer的子类)编写字符,并将写入的字符转换为 char 数组。在写入所有字符时,CharArrayWriter 上调用 toCharArray() 能很方便的生成一个字符数组
CharArrayWriter writer = new CharArrayWriter();
writer.append('H');
writer.write("ello ".toCharArray());
writer.write("World");
char[] chars = writer.toCharArray();
writer.close();
CharArrayReader reader = new CharArrayReader(chars);
int data = reader.read();
while (data != -1) {
System.out.print((char) data); // Hello World
data = reader.read();
}
reader.close();字符流的处理流实现
PrintWriter - 字符输出流
一般用于文件写出,有一个好的构造函数:
public PrintWriter(File file) throws FileNotFoundException {
this(new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file))),
false);
}提供的println和print方法,分别适用于自动换行和不换行
public void println(String x) {
synchronized (lock) {
print(x);
println();
}
}相比于BufferedWriter,PrintWriter更适合完成文件写出工作,这是因为:
PrintWriter的print、println方法可以接受任意类型的参数,而BufferedWriter的write方法只能接受字符、字符数组和字符串;
PrintWriter的println方法自动添加换行,BufferedWriter需要显示调用newLine方法;
PrintWriter的方法不会抛异常,若关心异常,需要调用checkError方法看是否有异常发生;
PrintWriter构造方法可指定参数,实现自动刷新缓存(autoflush);
PrintWriter的构造方法更广。
RandomAccessFile - 随机访问文件
设计思路
public class RandomAccessFile implements DataOutput, DataInput, CloseableRandomAccessFile虽然是流的一部分,并且实现了DataOutput、DataInput接口,但是它并非四种流抽象类(InputStream、OutputStream、Reader、Writer)任何一种下的实现,换言之,它是一个完全独立的流
RandomAccessFile提供的功能是对文件的随机访问,包括输入和输出,其他流正常只支持一种,要么读要么写
RandomAccessFile把随机访问的文件对象看作存储在文件系统中的一个大型 byte 数组,然后通过指向该 byte 数组的光标或索引(即:文件指针 FilePointer)在该数组任意位置读取或写入任意数据。输入操作从文件指针开始读取字节(以字节为单位进行读取),并随着对字节的读取而前移此文件指针。如果RandomAccessFile访问文件以读取/写入模式创建,则输出操作也可用;输出操作从文件指针开始写入字节,并随着对字节的写入而前移此文件指针
相关方法
指针方法
RandomAccessFile包含三个方法来操作文件记录指针
long getFilePointer():返回文件记录指针的当前位置void seek(long pos):将文件记录指针定位到pos位置。这个指针位置超过了文件末尾并不会有什么影响,但写入了数据,则文件实际长度就会被修改skipBytes(int n):该方法用于尝试跳过输入的n个字节以丢弃跳过的字节(跳过的字节不读取)int skipBytes(int n):该方法可能跳过一些较少数量的字节(可能包括0),这可能由任意数量的条件引起,在跳过n个字节之前已经到大文件的末尾只是其中的一种可能。该方法不抛出EOFException,返回跳过的实际字节数,如果n为负数,则不跳过任何字节FileDescriptor getFD(): 可以返回这个文件的文件描述符native long length(): 可以返回文件的长度
native void setLength(long newLength): 还可以设置文件的长度,因为RandomAccessFile把文件视为数组,设置长度实际上就是在设置数组长度,如果小于文件实际长度,则文件被阶段,如果大于,则后面部分视为未定义内容close(): RandomAccessFile在对文件访问操作全部结束后,要调用close()方法来释放与其关联的所有系统资源
读方法
int read():从此文件中读取一个数据字节。int read(byte[] b):将最多 b.length 个数据字节从此文件读入 byte 数组。int read(byte[] b, int off, int len):将最多 len 个数据字节从此文件读入 byte 数组。boolean readBoolean():从此文件读取一个 boolean。byte readByte():从此文件读取一个有符号的八位值。char readChar():从此文件读取一个字符。double readDouble():从此文件读取一个 double。float readFloat():从此文件读取一个 float。void readFully(byte[] b):将 b.length 个字节从此文件读入 byte 数组,并从当前文件指针开始。void readFully(byte[] b, int off, int len):将正好 len 个字节从此文件读入 byte 数组,并从当前文件指针开始。i
nt readInt():从此文件读取一个有符号的 32 位整数。String readLine(): 从此文件读取文本的下一行。long readLong():从此文件读取一个有符号的 64 位整数。sh
ort readShort():从此文件读取一个有符号的 16 位数。int readUnsignedByte():从此文件读取一个无符号的八位数。int readUnsignedShort():从此文件读取一个无符号的 16 位数。String readUTF():从此文件读取一个字符串。
写方法
void write(byte[] b):将 b.length 个字节从指定 byte 数组写入到此文件,并从当前文件指针开始。vo
id write(byte[] b, int off, int len):将 len 个字节从指定 byte 数组写入到此文件,并从偏移量 off 处开始。void write(int b):向此文件写入指定的字节。void writeBoolean(boolean v):按单字节值将 boolean 写入该文件。void writeByte(int v):按单字节值将 byte 写入该文件。void writeBytes(String s):按字节序列将该字符串写入该文件。vo
id writeChar(int v):按双字节值将 char 写入该文件,先写高字节。void writeChars(String s):按字符序列将一个字符串写入该文件。void writeDouble(double v):使用 Double 类中的 doubleToLongBits 方法将双精度参数转换为一个 long,然后按八字节数量将该 long 值写入该文件,先定高字节。void writeFloat(float v):使用 Float 类中的 floatToIntBits 方法将浮点参数转换为一个 int,然后按四
评论区