


Pulsar的架构
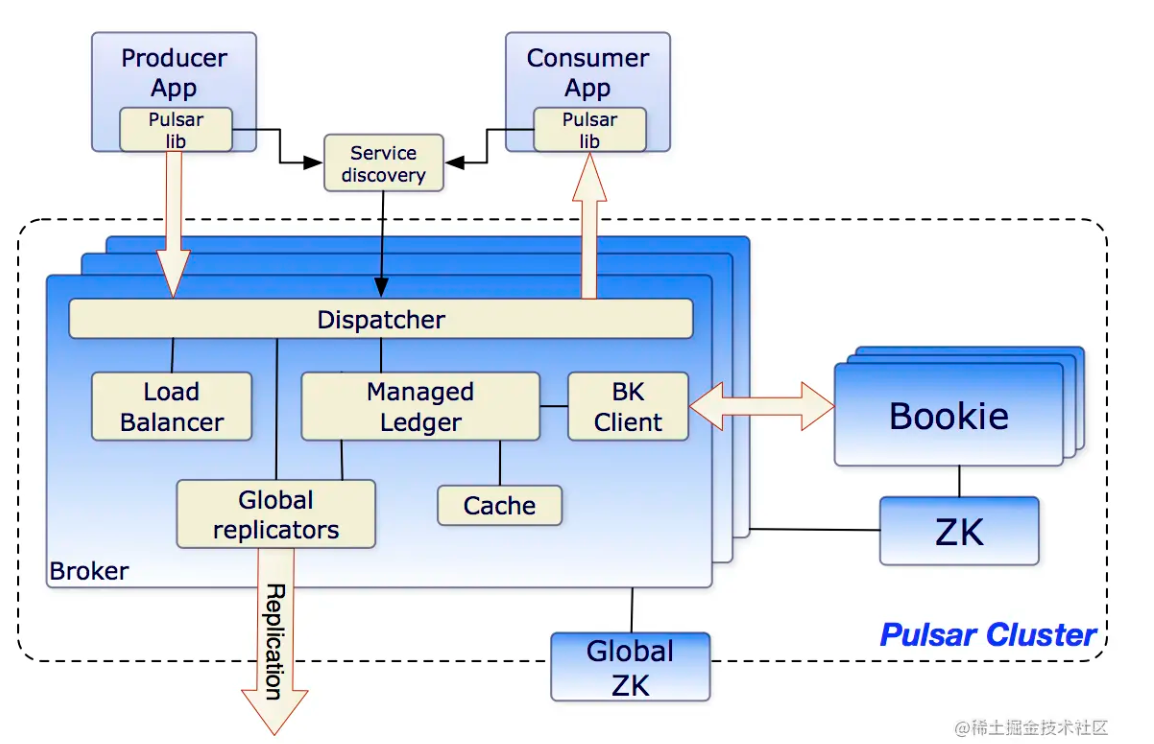
Broker:Broker负责消息的传输,Topic的管理以及负载均衡,Broker不负责消息的存储,是个无状态组件。
Bookie:负责消息的的持久化,采用Apache BookKeeper组件,BookKeeper是一个分布式的WAL系统。
Producer:生产者,封装消息并将消息以同步或者异步的方式发送到Broker。
Consumer:消费者,以订阅Topic的方式消费消息,并确认。Pulsar中还定义了Reader角色,也是一种消费者,区别在于,它可以从指定置位获取消息,且不需要确认。
Zookeeper:元数据存储,负责集群的配置管理,包括租户,命名空间等,并进行一致性协调。
此外Pulsar与Kafka一样,也具有producer、topic、consumer这些概念
Pulsar与kafka的比较
Kafka已经是比较成熟的消息中间件了,为什么还要学习Pulsar,主要基于以下区别对比
存储模式
Kafka集群是由一个个broker(服务器)组成的,基于zookeeper进行调度,每个broker既承担计算任务又承担存储任务
Pulsar是算、存分层的:
Brokers:负责处理生产者和消费者的连接、消息传输、负载均衡、复制等计算密集型任务(无状态)。Pulsar的brokers也是基于zk进行协调的
BookKeeper:一个分布式的预写日志存储系统,专门负责消息的持久化存储(有状态)。
由于Pulsar这种特性,扩充计算节点只需要扩展broker而无需考虑数据存储的问题,而kafka的broker由于承担存储任务,每次横向扩展需要对数据进行再平衡
分段、分区
kafka的分段机制
kafka的消息是以topic进行分类的,每个topic下面的存储模式是分partition存储(每个topic有几个partition是在创建topic时指定的)
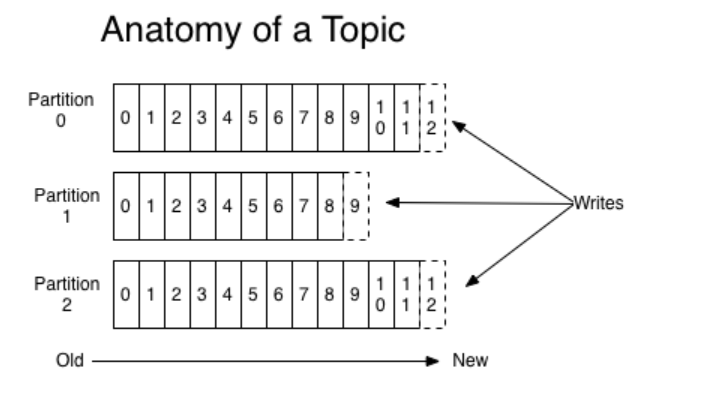
每个partition都是以文件系统的形式存储在硬盘上,假如有一个topic名称为myTopic设置为5个partition,那么会生成myTopic-1、myTopic-2...myTopic-5这些目录
每个partition存储了若干message,每个message的数据结构包含以下三个属性:
offset
MessageSize
data
如果把一条message当成数据库的一条数据,那么offset就是它的主键,根据offset可以唯一确定一条message
mysql的聚簇索引机制就是利用B+树,叶子节点存储数据,非叶子节点存储索引。当mysql的也一个页数据存满了,就会将其拆成两个页,并且为这两个页选出其中最小的两个主键值,存入一个新页,由这个新页作为父节点,即这两个数据页的索引
kafka的分段机制实际上也是类似的
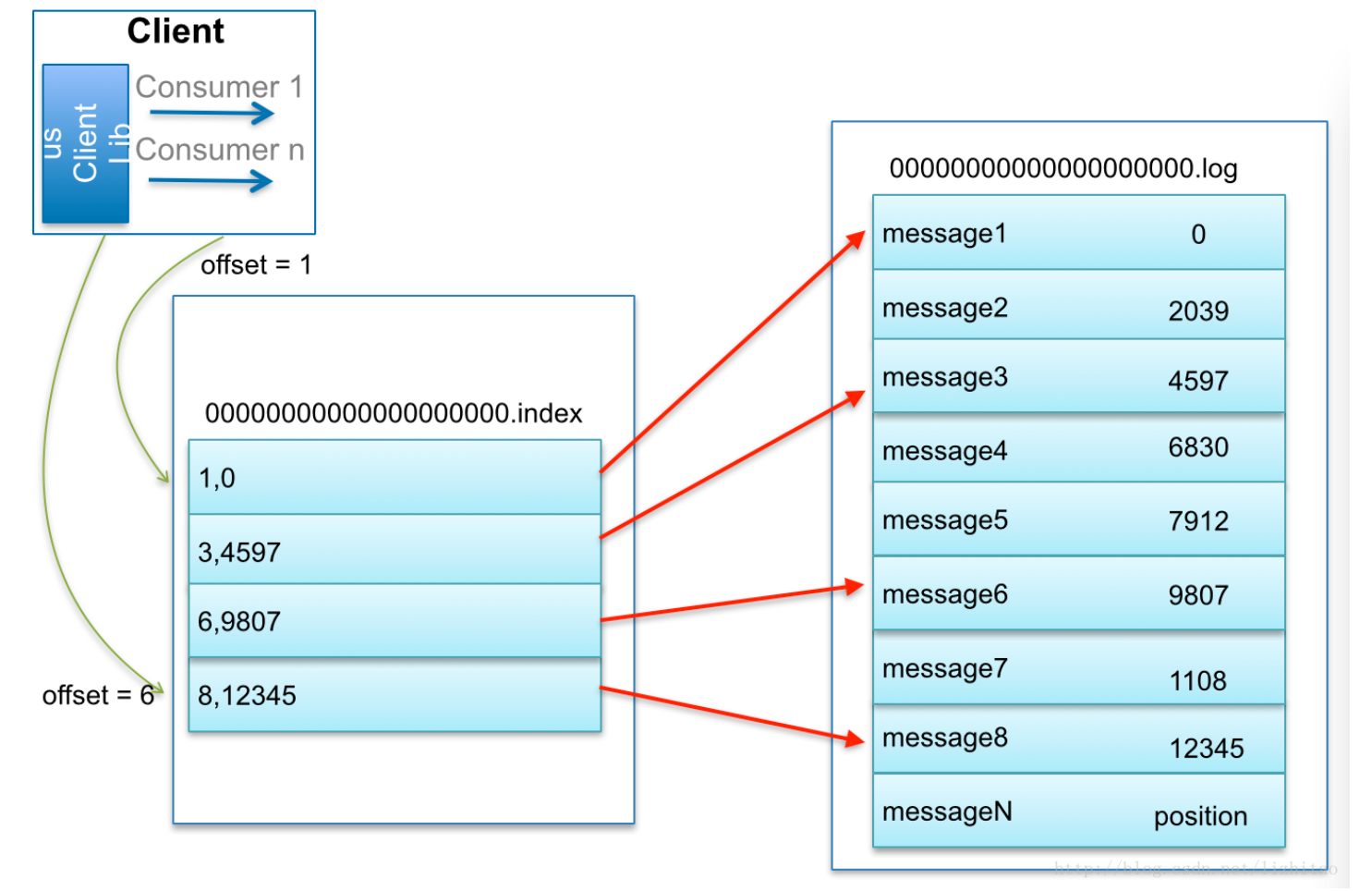
在每个partition中为所有的数据分成不同的segment,每个segment数据量固定,选出其中最小的offset存放到一个新的文件中,作为索引,查询数据时只需先通过二分查找检索索引文件,就可以找到对应的segment
在文件系统中,存储数据的segment对应的文件是.log文件,存储索引对应的文件是.index文件,二者都以这一段中最小的offset命名
Pulsar的分段机制
Pulsar采用的是逻辑分区-物理分段的机制
Pulsar与kafka类似,topic下面也是分为不同的partiton,partition也是分为不同的segment
但是Pulsar的partition并非以文件形式存储在磁盘上,而是将topic-partition和partition-segment的映射存储在全局元数据服务(ZooKeeper 或 Etcd)中
即partition不是一个真实概念,而是一个抽象概念
此外,segment是动态生成的,假设每个segment上限是1000M,一个topic达到上限后,会在bookeeper中任意节点上申请一个新的segment继续存储,而老的达到上限的segment则变成只读模式,甚至可以整体迁移到成本更低的存储介质中
而回顾kafka,由于是文件系统存储,则一个topic只能固定存储在一台节点上
因此kafka的单个topic性能受到单个节点性能限制,而Pulsar一个topic性能和吞吐量则是由整个集群决定的
ZK在Pulsar和kafka中承担的角色
zk作为分布式配置系统、全局元数据服务,在Pulsar和kafka中承担的角色也不太一样
在kafka中,zk主要作为broker节点注册、选举leader等能力的寄托,可以理解为kafka的信息中枢,本质上就是在zk上面开个节点存储信息
在pulsar中,zk还作为存储映射关系的数据仓库,因此也在Pulsar节点扩容等工作中起到一定作用,同时还会存储一些集群元数据信息例如cpu、内存等
消费模型
kafka的消费模型
两种:发布订阅、点对点
这两种消费模型的基础都是kafka的consumer group消费者组
在kafka中,一个consumer并不一定能消费全部消息,而一个consumer group一定可以,因为消费的条件是一个topic被一个consumer group消费时,必须将所有的partition分配给其中的consumer,这个逻辑有三个关键点:
一个partition只能被一个consumer消费
一个consumer可能消费一个或多个partition
kafka消息只会被存储在一个partition中
假设一个topic共3个partition,来分析以下几个场景
一个java服务消费一个topic:这个服务只需要轮询所有的consumer就可以消费这个topic中所有的消息
创建1个consumer:这个consumer消费全部三个partition,是通过串行的方式消费的
创建2个consumer:一个consumer必须消费2个partition
创建3个consumer:每个consumer消费1个partition
创建4个consumer:有一个consumer闲置,不推荐
两个java服务消费一个topic
使用同一个consumer group:那么这两个java服务中的consumer只能消费到topic中的部分消息,必须引入全局redis、mysql等维护消息一致性;
使用不同的consumer group:两个java服务各自消费,互不干涉
以下两个注意点非常重要:
每个consumer group维护一个offset来实现消息消费偏移量,每次消费完成,offset都向后移动,如果分布式的服务共同使用同一个consumer group,在一个pod消费后宕机,可能导致offset未更新,下一个pod可能再次消费同一个offset,导致消息重复,因此必须对消息进行重复性校验
如果有一个新的consumer group对消息进行消费,会维护一个新的offset,这个offset默认指向该topic最新一条数据,即新加入的消费者组从该topic下一条新消息开始消费;如果有消费历史消息的需求,则必须使用
auto.offset.reset=earliest属性,但是这种场景要非常警惕消息浪涌,因为不知道历史到底有多少未消费的记录
现在再来结合consumer group来回看kafka的两种消费模型:
点对点:即一个topic被唯一的consumer group消费,常用于唯一性场景,例如一笔订单只能被处理一次,与RabbitMQ、RocketMQ类似
发布订阅:即多个consumer group消费一个topic,常用于监控场景,例如湿度传感器、温度传感器等都监控今天的天气变化信息,与Redis发布订阅类似
Pulsar的消费模型
Pulsar的消费模型的核心是订阅subscribe,生产者发布消息,consumer订阅消息,每个subscribe维护一个cursor标记消费的位置,有以下几种订阅类型:
独占:严格控制一个topic仅能被一个consumer订阅,该类型消息消费是全局严格有序的,在该consumer消费完成后进行ACK给broker对BookKeeper中的cursor进行更新
// 消费者1 - 成功连接
Consumer<byte[]> consumer1 = pulsarClient.newConsumer()
.topic("exclusive-topic")
.subscriptionName("exclusive-sub")
.subscriptionType(SubscriptionType.Exclusive)
.subscribe(); // 成功
// 消费者2 - 相同订阅尝试连接
Consumer<byte[]> consumer2 = pulsarClient.newConsumer()
.topic("exclusive-topic")
.subscriptionName("exclusive-sub") // 同名订阅
.subscriptionType(SubscriptionType.Exclusive)
.subscribe(); // 抛出异常:ConsumerBusy共享:类似kafka的consumer group,多个consumer可以订阅一个topic,每个consumer轮询消费,即他们消费的消息是不同的,在这个类型下,消息消费是完全无序的,每个consumer都在消费完成后进行ACK,让broker更新cursor,这时由broker进行合并处理,完成最终更新
故障转移:本质上是独占类型的扩展,只有一个consumer为主,其他为备,当主consumer宕机,竞争选举新的主consumer,这个类型下消费是在主备机上保证顺序的,只有主机消费后进行ACK可以通知broker更新cursor
key共享:多个conusmer消费消费同一个topic,相同Key路由到固定消费者
// 创建 Key_Shared 消费者(支持用户行为有序跟踪)
Consumer<byte[]> consumer = pulsarClient.newConsumer()
.topic("user-events")
.subscriptionName("user-profile-sub")
.subscriptionType(SubscriptionType.Key_Shared) // 关键设置
.keySharedPolicy(KeySharedPolicy.autoSplitHashRange() // 自动分片
.ackTimeout(10, TimeUnit.SECONDS)
.subscribe();
// 处理消息(相同Key的消息由固定消费者处理)
Message msg = consumer.receive();
String userId = msg.getKey(); // 根据Key保证有序
processUserEvent(userId, msg.getData());
consumer.acknowledge(msg);前面提到broker无状态,实际上指的就是broker不存储cursor,只代理ACK请求到bookKeeper,正是因为cursor是独立存储的,因此可以任意更新到历史位置
ACK的方式有:
单条ACK:完成消费立即ACK推进cursor更新,适合金融场景
Message<byte[]> msg = consumer.receive();
consumer.acknowledge(msg); // 立即更新cursor到该消息后累计ACK:cursor跳跃到指定ACK消息之后
Message<byte[]> msg = consumer.receive();
consumer.acknowledgeCumulative(msg); // 确认该消息及之前所有消息负ACK:不更新cursor,触发重投
try {
Message<byte[]> msg = consumer.receive();
process(msg);
} catch (Exception e) {
consumer.negativeAcknowledge(msg); // 不更新cursor,触发重投
}Pulsar集成与样例
pom
<dependency>
<groupId>org.apache.pulsar</groupId>
<artifactId>pulsar-client</artifactId>
<version>2.11.0</version> <!-- 使用最新稳定版本 -->
</dependency>客户端创建
import org.apache.pulsar.client.api.PulsarClient;
import org.apache.pulsar.client.api.PulsarClientException;
public class PulsarClientFactory {
private static final String SERVICE_URL = "pulsar://localhost:6650";
private static PulsarClient client;
public static synchronized PulsarClient getClient() throws PulsarClientException {
if (client == null) {
client = PulsarClient.builder()
.serviceUrl(SERVICE_URL)
.ioThreads(4) // 优化IO线程
.listenerThreads(10) // 监听线程数
.build();
}
return client;
}
public static void shutdown() {
try {
if (client != null) {
client.close();
}
} catch (PulsarClientException e) {
// 处理异常
}
}
}Pulsar的配置项枚举在org.apache.flink.connector.pulsar.common.config.PulsarOptions
生产者创建
import org.apache.pulsar.client.api.Producer;
import org.apache.pulsar.client.api.PulsarClient;
import org.apache.pulsar.client.api.PulsarClientException;
import org.apache.pulsar.client.api.Schema;
public class PulsarProducer {
private final Producer<String> producer;
private String topic = "persistent://public/test_namespace/fatfish_test_topic";
public PulsarProducer(String topic) throws PulsarClientException {
this.producer = PulsarClientFactory.getClient()
.newProducer(Schema.STRING)
.topic(topic)
.blockIfQueueFull(true) // 防止生产者队列满时丢失消息
.create();
}
public void sendMessage(String message) {
try {
// 同步发送
producer.send(message);
// 异步发送(高性能场景)
// producer.sendAsync(message)
// .thenAccept(msgId -> log.info("消息发送成功: {}", msgId))
// .exceptionally(ex -> {
// log.error("发送失败", ex);
// return null;
// });
} catch (PulsarClientException e) {
// 处理异常
}
}
public void close() {
try {
producer.close();
} catch (PulsarClientException e) {
// 处理异常
}
}
}消费者创建
import org.apache.pulsar.client.api.*;
import java.util.concurrent.TimeUnit;
public class PulsarConsumer {
private final Consumer<String> consumer;
public PulsarConsumer(String topic, String subscriptionName)
throws PulsarClientException {
this.consumer = PulsarClientFactory.getClient()
.newConsumer(Schema.STRING)
.topic(topic)
.subscriptionName(subscriptionName)
.subscriptionType(SubscriptionType.Shared) // 共享订阅
.ackTimeout(30, TimeUnit.SECONDS)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(3)
.deadLetterTopic(topic + "-DLQ")
.build())
.subscribe();
}
public void startConsuming() {
new Thread(() -> {
while (true) {
try {
// 接收消息(带超时)
Message<String> msg = consumer.receive(100, TimeUnit.MILLISECONDS);
if (msg == null) continue;
processMessage(msg);
consumer.acknowledge(msg);
} catch (PulsarClientException e) {
// 处理异常
}
}
}).start();
}
private void processMessage(Message<String> msg) {
try {
System.out.println("收到消息: " + msg.getValue());
// 业务处理逻辑...
} catch (Exception e) {
// 处理失败,触发重试
consumer.negativeAcknowledge(msg);
}
}
public void close() {
try {
consumer.close();
} catch (PulsarClientException e) {
// 处理异常
}
}
}这里需要注意的是,receive方法只会拉取一次,如果拉去不到,结果是null,应进行判定防止抛出空指针异常
Admin创建
PulsarAdmin admin = PulsarAdmin.builder().serviceHttpUrl("http://localhost:8080").authentication(AuthenticationFactory.token(JWT)).build();
List<String> namespaces = admin.namespaces().getNamespaces("public");
for (String namespace : namespaces) {
System.out.println("namespace: " + namespace);
}
admin.namespaces().createNamespace("public/test_namespace");与Pulsar客户端使用的pulsar://localhost:6650 协议不同,admin使用的是http://localhost:8080 协议
admin的一个重要作用是创建tenent、namespace和topic
在pulsar中,topic的格式一般是:String topic = "persistent://public/test_namespace/fatfish_test_topic";
其中:public是tenent,test_namespace是namespace,fatfish_test_topic是topic,除了public是默认存在的(当然,不想用public也可以自己单独搞一个),必须逐级创建
admin.namespaces().createNamespace("public/test_namespace");如果namespace已经存在了,再创建同名topic就会抛出org.apache.pulsar.client.admin.PulsarAdminException$ConflictException: Namespace already exists 异常,因此要对namespace做检查
topic同理:
List<String> topics = admin.topics().getList("public/billing_namespace");
for (String topic : topics) {
if (topic.startsWith("persistent://public/billing_namespace/fatfish_test_topic")) {
topicExists = true;
break;
}
}
if (!topicExists) {
admin.topics().createPartitionedTopic("public/test_namespace/fatfish_test_topic", 3);
}但是需要注意的是,这里创建分区topic,实际创建出来是fatfish_test_topic-1...,因此判定要使用startWith方法,并且topic输出的是persistent协议名开头,与namespace不太一样
同样,如果创建同名topic,会抛出异常org.apache.pulsar.client.admin.PulsarAdminException$ConflictException: This topic already exists
评论区